originally appeared on Crossref blog (full story here)
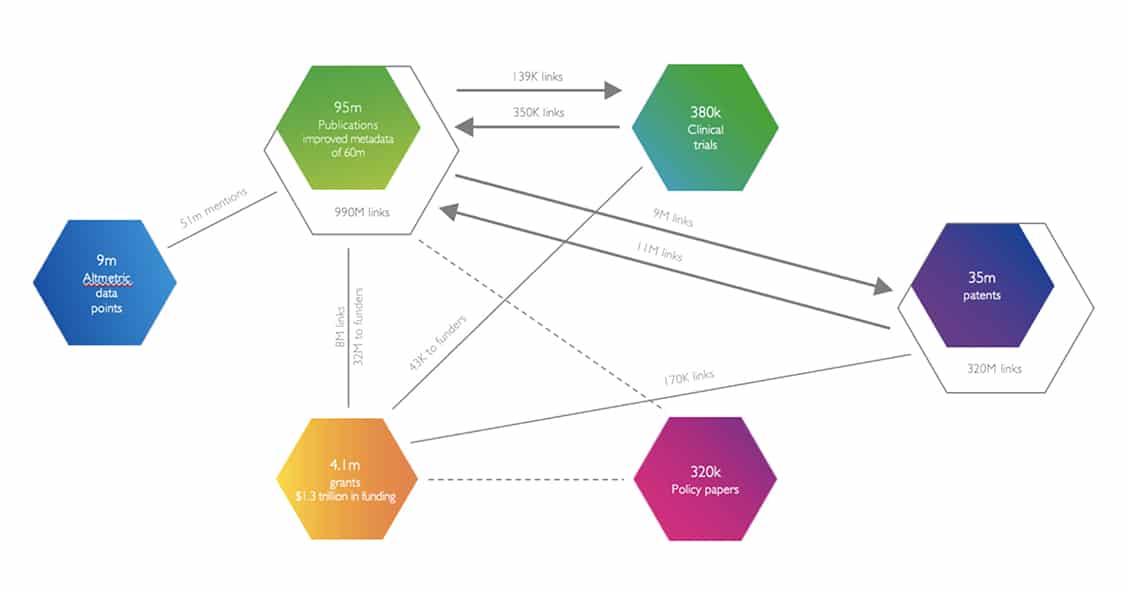
For an article to appear in Dimensions it must have a Crossref DOI, so it would not be possible to create Dimensions’ Publication index without Crossref’s data. Dimensions is built on several principles that we’ve talked about before. Here the most relevant of those principles are:
- unique identifiers should underlie everything that we do;
- data should not be inclusive and the tool should allow the user to select what they want to see;
- data should be more available to our community;
- data should be presented with as much contextual information as possible;
- the community should have enough data available to be able to create and experiment with their own metrics and indicators.
In the context of these principles, Crossref makes a perfect starting place to create a tool like Dimensions. We use the Crossref data to know about our possible “universe” of articles. We then enhance the Crossref core with data from several different places: open access publications in the DOAJ, PubMed, BioArXiv, and through relationships with publishers. In all, 60 million of the 95 million articles in the Dimensions index have a full text version that we can text and data mine for additional information.
In Dimensions’ enhancement stage we can extract address information (where not included in the original Crossref record) and map it to GRID funding information and the list of funders in Crossref’s Funder Registry as well as to our database of grants in Dimensions.
To read more about the uses of Crossref metadata, read the full Crossref blog series.