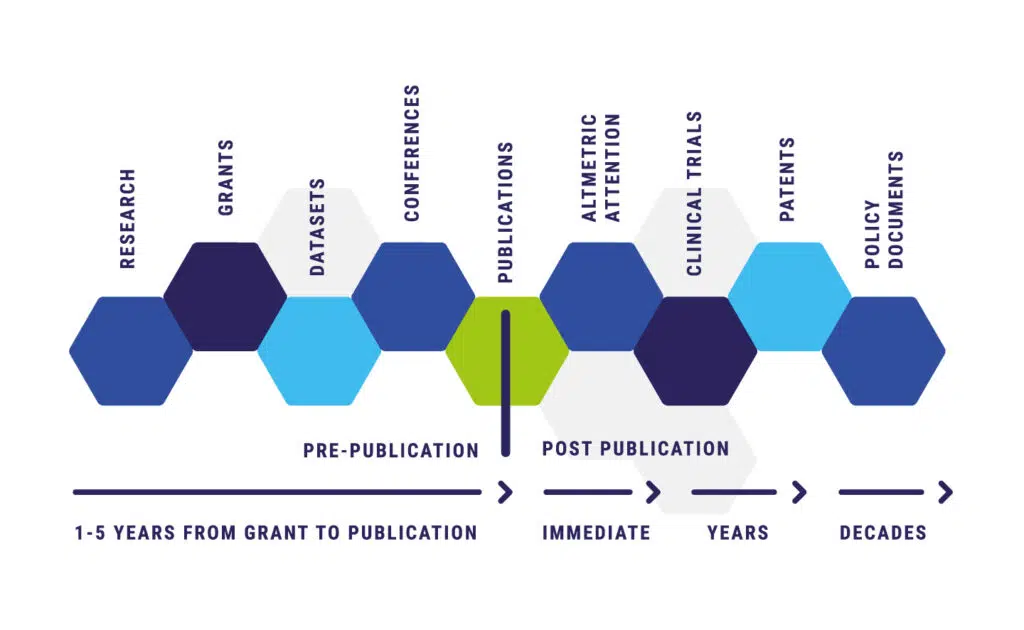
The data in Dimensions – from idea to impact
The world’s largest collection of linked research data
Size and enrichments matter
Not only is Dimensions the world’s largest research information database, our clear goal is to enrich and link the data for you as much as possible: with keywords and concepts, organizations, researchers, or machine learning-based classifications. This brings thousands of data silos together in one linked data set for you – ready to be explored.
Get ahead of the curve
Dimensions speeds up the insight needed to develop smarter strategies and breakthrough innovations.
See the past, present and future of research by:
- Analyzing the impact of clinical trials, patents and policies
- Sourcing information from journals worldwide, as well as preprints, datasets, proceedings and books
- Identifying future trends by following grant funding
More than a database
With deep indexing of more than 98 million publications and 150 million patents, Dimensions provides enriched data that makes research easier. This includes specific, disambiguated data on individual people as well as institutions, using AI-based categorization and a wide range of indicators and metrics.
Looking into the future
Using Dimensions yields a 360-degree view of all research, including researcher profiles, institutional profiles and global trends. From that wide perspective, you can utilize the power of natural language processing, AI and machine learning to gain insights from across a huge range of documentation and data.
Dimensions’ range and sophistication of search capabilities means you’ll be able to understand who and what is driving scientific discovery, where the next related innovation may come from, and who you’ll need to collaborate with to make it happen.

The ultimate research tool
Dimensions’ accessibility and flexibility really set us apart from our competitors. Providing data in all the different ways users require, Dimensions offers:

- One of the world’s most powerful search applications
- Visual dashboard apps that help solve specific research challenges
- The Dimensions API, which can be used to build your own applications
- Raw data through Dimensions on Google BigQuery in a relational database, enabling large-scale analysis and integrated data into other systems.
Dimensions enriches data… and the value of your research
Why Dimensions?
At Dimensions we want our data to help you in your research discovery. We meticulously resolve metadata and help you find connections across the research ecosystem easily and at speed.
With three times more resolved funding references and links to over 7 million global grants and over 144 million publications, we prioritize precision over recall and provide you with advanced visual analytics, empowering you with better discovery tools, transparency, and streamlined processes.
Take a look at our comparison table to see how Dimensions data compares to other A&I databases.
| Dimensions | Scopus | Web of Science | Open Alex | |
|---|---|---|---|---|
| Total Content Records | ~391M | ~120M | ~164M | ~256M |
| Publications | 164M | ~70M | ~87M | ~256M * |
| Preprints | 4.3M | ~1.9M | 2M | N/A |
| Datasets | 42M | ✗ | ✗ Only available via subscription to the Data Citation Index; 13M) | 7.5M |
| Grants | 8.1M | ✗ | ✗ Only available via subscription to the Grants Index; 5.7M | 121K |
| Patent records | 170M | ~49M | ✗ (Only available via subscription to the Derwent Innovation Index; 57M) | ✗ |
| Clinical trials | 938K | ✗ | ✗ | ✗ |
| Policy documents | 2.5M | ✗ | ✗ Only available via subscription to the Policy Citation Index; 210k | ✗ |
| Links between all content types | ✓ | ✗ | ✗ | ✓ ** |
| Search in title & abstract only | ✓ | ✓ | ✓ | ✗ |
| Advanced search | Boolean, GUI | Boolean, GUI | Boolean, GUI | Boolean, GUI |
| Search in fulltext | ✓ | ✗ | ✗ | ✓ *** |
| Search by pasting an abstract | ✓ | ✗ | ✗ | ✗ |
| Multiple and open classification systems | ✓ | ✗ | ✗ | N/A |
| Dissertations | No | ✗ | ✓ | 6M |
| Classifications | Article-level – all content types | Journal-level | Journal-level | Work-level |
| Citations and metrics | Citations, FCR, RCR, Highly cited, Recent Citations, Altmetric Attention Score, Patent citations, SNIP, SJR | Citations, FWCI, Plum, SNIP, SJR, Recent Citations, h-index, CiteScore (tracker, percentile/quartiles, rank, citation and document count, cited) | Citations, Journal Impact Factor (JIF), CNCI (InCites), Eigenfactor Score, h-index, Article Influence Score | Citations |
164m
Publications
280m
Altmetric data points
938k
Clinical Trials
170m
Patents
2.5m
Policy Documents
8.1m
Grants
42m
Datasets
* This number is classified as ‘works’ and is not limited to publications but also other content types
** Finds associations between journals, authors, institutional affiliations, citations, concepts, and funders.
*** Full-text search is only available on Open Access documents.
Notes
- This comparison aims to help potential users make an informed decision on the most suitable tool for research discovery. If you have any suggestions about how it could be improved please get in touch with support.
- Information relating to Dimensions relates to Dimensions Analytics as of July 2025.
- Scopus is owned by Elsevier. Information included relates to Scopus and was sourced from its website in June 2025.
- Web Of Science is owned by Clarivate. Information included relates to Web of Science and was sourced from its website in June 2025.
- Open Alex is owned by Our Research. Information included relates to Open Alex and was sourced from its website in June 2025.
Case Studies
Examples of how Dimensions and its powerful and flexible tools have helped researchers around the world



FAQs
Analysis of clinical trials, patents, policies, journals, datasets, and future trends are all possible with Dimensions Data.
Dimensions Data offers Boolean and GUI advanced search, as well as search by title and abstract, full-text, and pasting an abstract.
Yes, the Dimensions API can be used to build your own application to utilize data in a way that suits your needs best.