Would you like a database of 89 million publications, together with citation counts, linked grants, patents and clinical trials? Maybe with affiliation data and researcher disambiguation? Would you like some of it for free and the rest at low cost?
You would? Then good news for you this week! We’re incredibly proud to be launching Dimensions, our new platform for analysis & discovery.
You can go check it out now at app.dimensions.ai. There’s no registration or anything required to get started. Run searches like this…
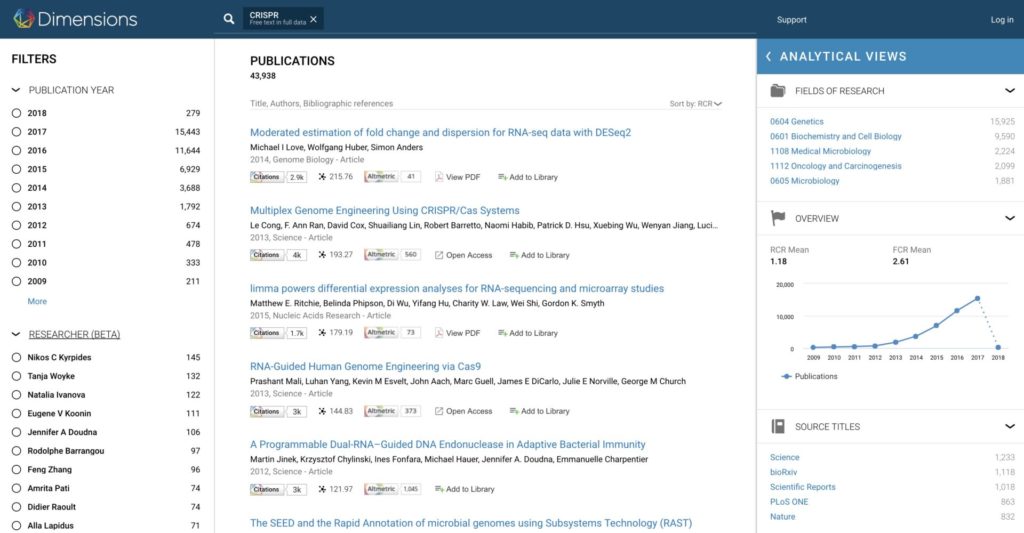
and you’ll get back thousands of results you can filter further by subject area, journal, year, open access status and more. The results have Altmetric Badges and citations in a new citations badge too. Oh yeah – we also launched citation badges and accompanying API that are free for non-commercial use: you can use them to add citation displays to CVs, lab homepages, blogs or whatever else you might like.
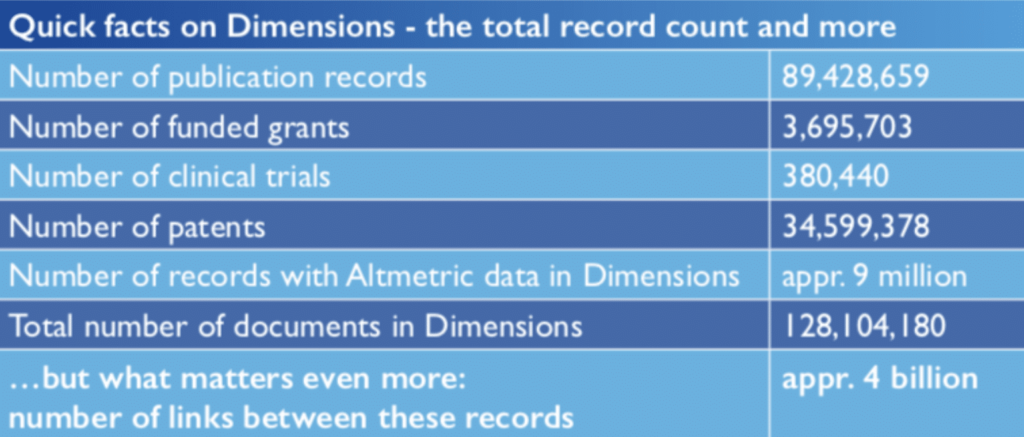
It gets even more exciting if your research organization gets involved – on top of an index of scholarly publications you get access to millions of patents, grants and clinical trials, in total 128 million documents, all searchable and linked together wherever possible – with 4 billion connections. It also gives you access to a more powerful API that accepts arbitrary queries in a simple domain search language so that you can pull out the data you need for your own dashboards, reports and applications.
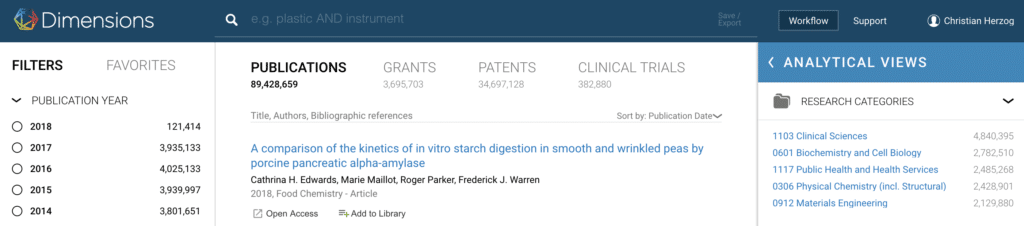
To build the citation network – over 873 million large – we’ve indexed tens of millions of documents and performed reference extraction on them, as well as pulling in other datasets like Crossref (the I4OC deserve credit here). We’ve extracted affiliations and mapped them to GRiD, and disambiguated 20 million researchers.
As anybody who works with scholarly metadata knows pulling together this kind of data while keeping quality high can be tricky, so we’ve been working closely with many scholarly publishers to make sure their metadata and indexing is as good as it can be.
There’s lots more to explore – see the website for more. In this post, though, we wanted to cover some of the background to Dimensions and talk a bit about where it’s headed.
Why did we build it?
Though it’s launching under the Digital Science brand, Dimensions is a collaboration between six different companies – UberResearch, Readcube, Altmetric, Symplectic, DS Consulting and figshare – and around one hundred research organization and funder development partners. We invested heavily in a small core team of three Dimensions only colleagues’ and then individual portfolio companies contributed staff, data, development effort and expertise, guided by invaluable real world feedback from the external development partners.
We did it because Dimensions is the kind of tool that customers have been telling us all individually that they want for years. It’s the kind of dataset that we wish had been around when we all got started building our products. It’s also a way for us to gently push for positive change, as we have with our other products.
We want to:
- Help researchers with discovery – by contextualising results, and delivering full text where possible
- Stop focusing only on publications & citation counts – by helping people take a broader view
- Not silo data about scholarly activity – by bringing it all together and linking it up
- Spark innovation & help people with good ideas put them into practice – by making the data readily available
As hand wavy as it sounds, at this point we’d love to have not just customers but users who’ll help us to shape this agenda and Dimensions in the future, which is why we’ve made it super easy for users to give us feedback and will continue to run the development partner program.
Of course Dimensions does need to be sustainable for us, too. For institutional use we’ve settled on something that covers our costs – much lower than competing products – with commensurate extra value in the form of extra datasets and flexible API use. Find out more about how your organisation can take advantage of the data and the tool. For individual use, searching across publications and their associated citations is free.
Much of what Dimensions does is built on earlier work from the companies involved, but we also owe a debt of thanks to several fantastic community initiatives like ORCID (integration with ORCID to come shortly after launch), Unpaywall for OA data (special thanks to Heather and Jason), I4OC and Digital Science’s own GRiD. All four are powerful enablers and we hope that Dimensions is a good example of the kinds of tools that can be built on top of them and the work that their supporters do.
If you want to learn about the data fueling Dimensions and the approach to bring it together, enrich and heavily link it – we prepared an overview in a larger document since it requires more space than a blog post – enjoy!
Where next?
We think the current release is a great starting point and we wanted to get the data out there as soon as we could. There are lots of places where we can make things even better though, either by adding or enriching more data or by adding new functionality.
Key to this will be getting your feedback, good or bad. Good will keep the team energized, and bad will help us improve, so do feel free to send it in and keep it coming. In the app itself you can click on the “Support” link in the top toolbar and then “Send feedback”. Alternatively you can catch us at a conference or email us direct at info@dimensions.ai.
We’ll also be reaching out directly to some communities to ask for help on specific topics. You might notice that while we’ve calculated some essential metrics (like counts & field citation ratios) we’ve held back from anything too new or complex for the launch and focused on the discovery use case. That was deliberate – we want to approach things in a responsible way and work with external groups. The RCR, which we’ve been developing with the NIH, is one example of this. There’ll be more information on how to get involved later, if you’re interested.
We hope you enjoy Dimensions as much as we did planning and building it. Please discover new papers, find some interesting links, produce some insightful analysis… and build something amazing!