From Mark Hahnel (CEO and founder of figshare)
This blog post could also be called, ‘how we can help you get ALL of your datasets into your data repository.’ Today, most major research institutes are investing in solutions for all of their research outputs, from papers to datasets. This was originally driven by new policies from research funders all over the world. However, as we reported in our State of Open Data report, we’re also seeing researchers making data available due to publisher and institutional mandates.
You may be aware that figshare came about due to a need for a repository for files not suitable for the subject-specific repositories in existence. At the time Zenodo wasn’t around, which would have filled said gap! In fact, even to this day, a large amount of academics do not have subject-specific repositories. An analysis of which repositories academics are using has been very difficult to carry out until the recent launch of Dimensions.
If we take the 3 most well-known generalist repositories, figshare.com, Dryad and Zenodo, and search Dimensions for links to the DOIs of those specific repositories, you can see that academics have found the need to use a generalist repository over 30,000 times. You can also see that this number is growing fast, with over one-third of them coming in the last 12 months. In order to provide a better service to the clients who were after such functionality, we decided to import Dryad and Zenodo outputs into our system, thus providing a way to populate their repositories, whilst maintaining the original DOIs and metadata, so as not to dilute citation or Altmetric scores.

As this trend is not looking to slow down, we began thinking about how we can help aggregate these datasets and non-traditional research outputs (NTROs) based on a few specific parameters. For instance, we can filter based on research coming out of the 28 EU member states and provide a data repository with 10,000 items in from these 3 generalist repositories alone, a baby European Open Science Cloud (EOSC) some might say. We can instantly group 3,793 datasets funded by the NSF into their own automatically filled repository.
This also lined up with requests from some of our clients using a white-labeled version of figshare for their own data repository. The inquiries were based on wanting to know the impact of all data and NTROs to come out of their institution. There was also the concept of having all of these items available under one API, to pull through the metadata and if needed, the files themselves into other internal systems. This can also be grouped in many ways, from 1,700 files for the University of California libraries or nearly 1,000 from the University of Oxford, both of which are not currently working with figshare.
The growth of links to data depositions in figshare.com, Dryad and Zenodo over time from papers published by University of Oxford researchers
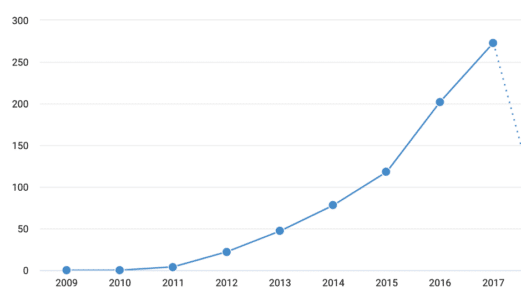
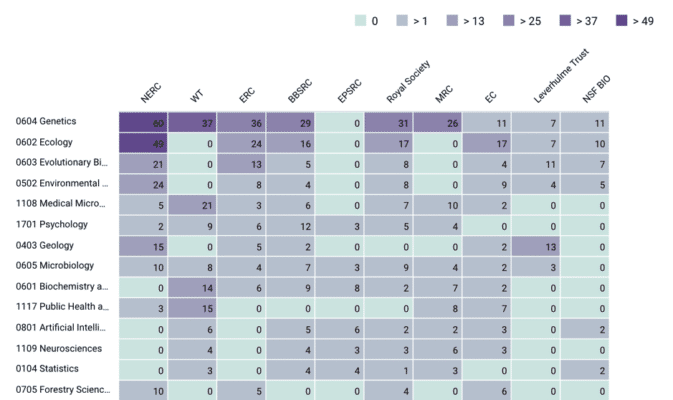
Taking the example of the University of Oxford, we can dig deeper into the findings using Dimensions. By confirming which funding bodies and which research areas this research is coming from, an institution can elucidate other helpful tidbits for guidance. The heatmap below quickly identifies which funders the academics are trying to fulfill mandates for. The categories identify areas where the penetration of this open data policy is both high and low, highlighting areas that require more engagement.
A second dimension to this is the large volume of data that is being sent to the publishers themselves. As the requirements around FAIR data continue to grow, the vast majority of publishers decided the technicalities of supporting data may fall outside of their remit, whilst a large proportion of academics still want to send all of the outputs associated with an article to the publisher. For this reason, figshare provides data infrastructure for a large number of publishers. For institutions to be able to aggregate all of their information into one place, we can also assist with any datasets that have been sent to these publishers.
This is of course, is the beginning of a huge task. re3data is the most comprehensive source of reference for research data infrastructures globally and offers detailed information on more than 2,000 research data repositories! Obviously, there is a long tail approach to this and we will start with the biggest ones first. But it does seem like there is a technological solution to this problem and we are happy to be working on it!
If you have any questions, feedback or comments, please get in touch at info@figshare.com.