“This is where the Dimensions API really shines.”
– Janne-Tuomas Seppänen, Information Specialist, Open Science Centre of the University of Jyväskylä, Finland
Janne-Tuomas Seppänen is an Information Specialist at the Open Science Centre of the University of Jyväskylä in Finland. His role is to design and build products and services to support researchers, research evaluation and societal impact.
As with other universities, it’s essential for the University of Jyväskylä to hire the best academic candidates.
“For the past decade or so, there’s been a growing awareness that the global academic community has been going about this the wrong way,” says Janne-Tuomas. “We’ve been looking at the number of publications and the impact factors of the journals in which people publish. And the community is realizing that this is a flawed way of assigning value to scientists and their research.”
A series of international guidelines (like DORA and CoARA) have called for more responsible, holistic evaluation of researchers based on substance and societal impact. The guidelines discourage the use of journal-based metrics (such as publication count or journal impact factor); they also recommend giving greater weight to the scientific content itself and considering a broader range of impact measures.
As Janne-Tuomas says, “It’s about relying primarily on the substance of the research, and its real impact, rather than the prestige of the vessels.”
The challenge of changing the assessment approach
Although most universities have signed up to these guidelines, there has been low implementation when it comes to recruitment. This applies to candidates and recruiters.
“We still see applications where the list of the candidate’s publications puts the journal name and impact factor in bold,” he continues. “You can’t blame the applicants, because that’s how the world works; the truth is that recruiters are accustomed to scanning the application quickly to see the names of the journals. The publication list is likely to be one of the first things that a hiring panel looks at – which breaches the commitment to do research assessments more responsibly.”
Janne-Tuomas and his team sat down to work on finding a practical way to do research assessments more effectively, in a way that would reduce bias and meet responsible assessment guidelines.
Reducing bias with automated evaluation
The solution the team came up with was an enriched, automated evaluation report, based on the applicant’s publication list but giving additional machine-generated summaries and metrics, and removing the journal name information to be at least one click away from the first impression.
This would enable the hiring panel to form their first impression of an applicant from a richer and more rounded view, instead of just their list of publications.
The team’s first goal was to create an automated way of gathering the applicant’s list publications. “We’re making metrics for hiring decisions, so we need to find all the publications we possibly can,” notes Janne-Tuomas. “But finding all the publications isn’t as easy as it sounds when you have to automate it and do it reliably.”
So how does the team go about it?
“First, the algorithm goes to the Dimensions API,” says Janne-Tuomas. “If we have the person’s ORCID it can search for their Dimensions researcher ID. Then the algorithm gets data from the API of ORCID and looks for any name changes or ID mismatches. It also takes the publication list PDF or DOCX document uploaded by the applicant and uses regex extraction to get a list of any DOIs included.”
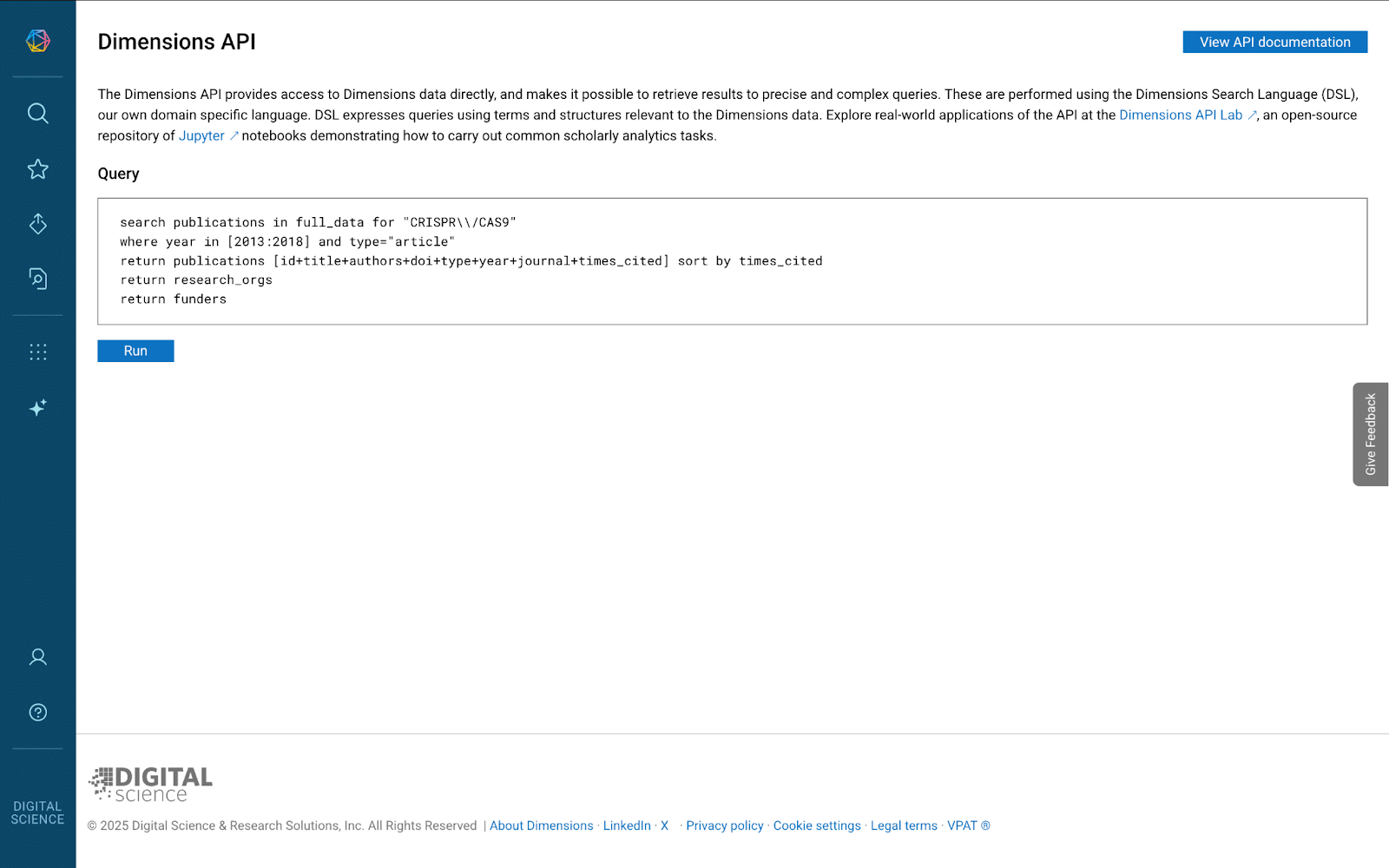
Dimensions Search Language (Click for higher resolution)

Dimensions API (Click for higher resolution)
Then it’s back to Dimensions to search for all the publications the team now knows to be the applicant’s. Equipped with the author data for all those articles, the algorithm can pick out user IDs that match with the name they have.
“Sometimes a single person might exist in Dimensions with several researcher IDs,” Janne-Tuomas continues. “So it does another Dimensions search with those user IDs to catch all the publications for those profiles. Then it adds anything we find to our existing collection.
“Now we have a full list of Dimensions-indexed publications for the applicant — or at least a very reasonable guess.”
Working the metadata magic
“With that done, we can go into the metadata magic part: doing the analysis,” Janne-Tuomas continues. “And first, we want a research summary. Why? Because if an applicant has already published 30 or 40 articles, and there are 50 applicants, no one will be able to read them all to judge their work. The hiring panel members won’t even have time to read all the abstracts. So we need to do some of that reading on behalf of the panel and summarize what the person is actually doing right now, or is going to do.”
The challenge here is the wide range of applicant seniority, experience and number of publications.
So the algorithm uses publication metadata to automatically pick 15 publications from the past 15 years, prioritizing articles where the applicant is a corresponding author. If that doesn’t produce 15 publications, it adds first-author articles, then last-author articles and finally any-authorship articles.
“This ensures we get a meaningful sample that represents early-career and senior applicants alike,” says Janne-Tuomas.
Working the metadata magic
Next, the team wants to get a sense of the applicant’s research impact. They use the Co-Citation Percentile Rank (CPR) via JYUcite, which leverages the Dimensions API.
CPR is an article-level indicator of citation impact. Instead of actual counts, CPR values provide fairer benchmarking by ranking an article’s citation rate within its co-citation network.
“This is where the Dimensions API really shines,” Janne-Tuomas enthuses. “We can pull the citation counts and publication dates of the entire co-cited article set of a target article with just a single API call – whereas doing this with other tools requires first pulling the citer set, then pulling the reference list of each citer separately, then doing two calls per each entry in each reference list.”
This quickly amounts to hundreds of API calls just to get the data to calculate a single CPR value.
To recognize a broader range of research impact, the team also considers policy citations using Overton, “which is again just a single API call using the DOI list built using Dimensions,” notes Janne-Tuomas.
For collaboration analysis, the team uses Dimensions authorship metadata to identify co-authors and visualize the applicant’s collaborative network. They emphasize the number of co-authors and highlight those with multiple collaborations, as well as countries or institutions represented.
“It really has tremendous efficiencies and the ability to express what you want to get out of the database in just a single call”
Saving time and improving assessment
All this – summary, impact and collaboration – is combined in an automatically generated report that makes it possible for the hiring panel to get a first impression with just a 300-word summary, familiarly tabulated impact statistics, and a graph of the collaboration network per every applicant. The report omits journal names, so first impressions aren’t shaped by where someone was published. This also opens the door to potential future implementation of anonymous first impressions, helping reduce bias related to gender or nationality.
As Janne-Tuomas explained earlier, by replacing the initial scanning of a publication list, the enriched automated report helps hiring panels focus on substance over prestige.
“We’ve already used this process in more than 20 international academic searches, from postdocs to professors across many disciplines,” he says. “And the reception from hiring panels has been positive.” Other universities and institutions have also expressed interest.
Janne-Tuomas sums up the goal: “Our aim is to help make responsible research assessment not just the declaration, but the default.”
Find out what Dimensions can do for you
Interested in how Dimensions can support your candidate assessment? Reach out to the team and improve your hiring process.